As mentioned in an earlier post, I have found it necessary to write out a formal workflow for PixInsight to map out the process. I started out with a pretty bare bones workflow and subsequently added in various additional steps as I became familiar with each of the tools. As of the time of writing, my workflow document (complete with screen captures of the various dialog boxes to remind me how everything works) runs to 35 pages. I am now adding in some additional steps to improve the image quality, but wanted to write something about how I got to this point.
The first step in designing the workflow is to divide all of the tasks into two groups: linear and nonlinear. If you read tutorials on each of the PixInsight tools, one of the items that is always called out is whether the tool works on linear or nonlinear data, and it is important not to mix these up.
 Raw data from the camera is in linear form, meaning that the pixel brightness values are directly proportional to the number of captured photons during the exposure (ignoring, for the time being, noise and other artifacts). Images in this form, displayed directly, look something like the image here; there is almost nothing visible except for some of the brightest stars.
Raw data from the camera is in linear form, meaning that the pixel brightness values are directly proportional to the number of captured photons during the exposure (ignoring, for the time being, noise and other artifacts). Images in this form, displayed directly, look something like the image here; there is almost nothing visible except for some of the brightest stars.
In order to make the image visible, some kind of nonlinear stretching has to be applied. This process is one way; once the data has been made nonlinear, there is no way to go back. This is why it is critical to always get data from a DSLR or CCD camera in RAW format: images in some other picture format such as JPG have already had nonlinear stretching applied, and there are important steps we need to apply to the linear data before we do that.
On the other hand, we also need some way of viewing the linear images in nonlinear form (just so we can see what we’re doing). In PixInsight, the Screen Transfer Function (STF) does this for us. It applies a stretch to the data that is shown on the screen without modifying the underlying data. This tool is much more sophisticated than the screen stretch function of Maxim DL or other tools, in that it applies a nonlinear stretch rather than just setting black and white points, and it can be used to determine the nonlinear stretch to be applied permanently to the data later in the workflow. I’ll describe this in more detail in a later post.
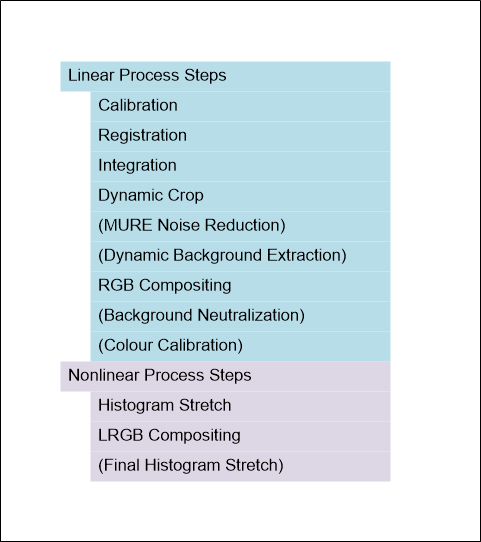 Taking that into account, my initial workflow looks like this. Some of the steps (in parentheses) could be dropped in a pinch just to create a simpler process. Note the division of steps into linear followed by nonlinear, with the data becoming nonlinear after the initial histogram stretch. As mentioned earlier, as additional steps are added to the workflow it is important to note which group they go into so as to fit them into the process at the most appropriate point.
Taking that into account, my initial workflow looks like this. Some of the steps (in parentheses) could be dropped in a pinch just to create a simpler process. Note the division of steps into linear followed by nonlinear, with the data becoming nonlinear after the initial histogram stretch. As mentioned earlier, as additional steps are added to the workflow it is important to note which group they go into so as to fit them into the process at the most appropriate point.
In subsequent posts, I will describe each of these steps (at least so far as I am using them right now) in some more detail.